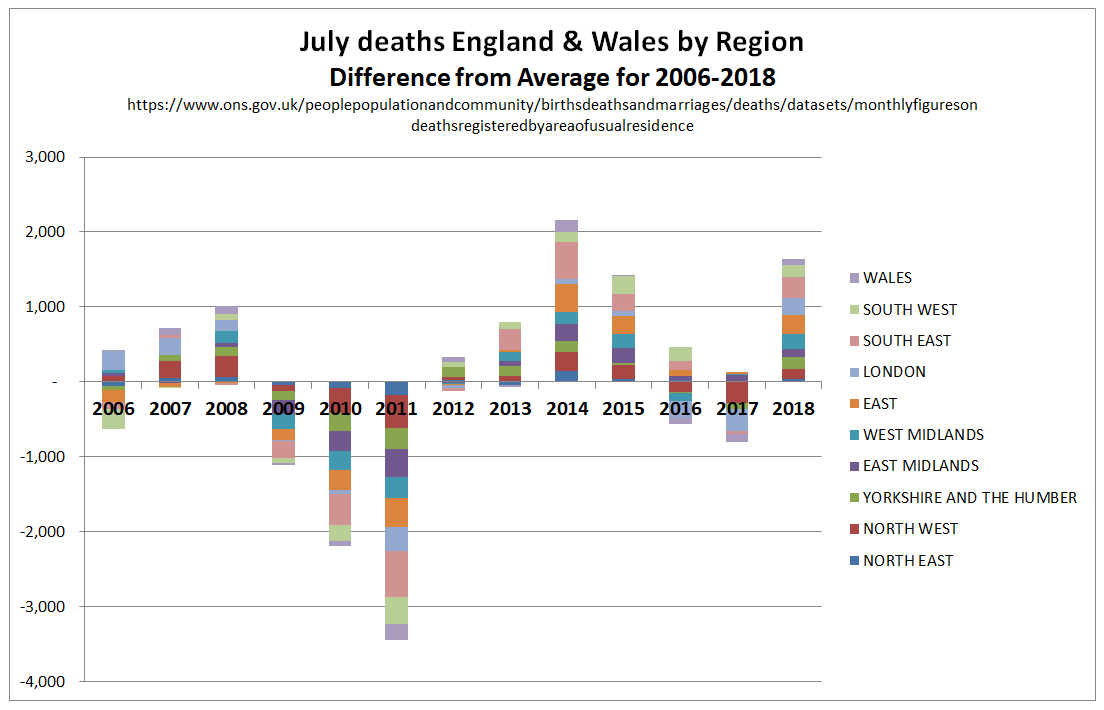
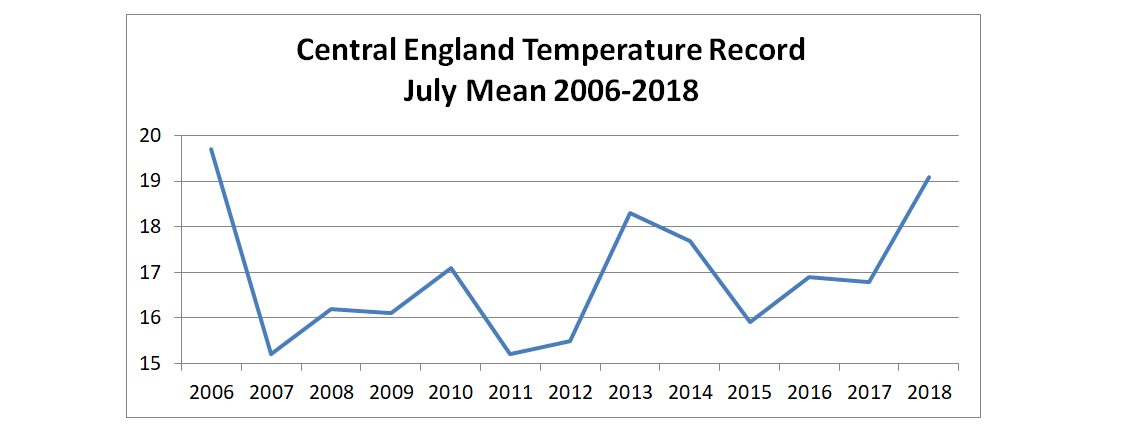
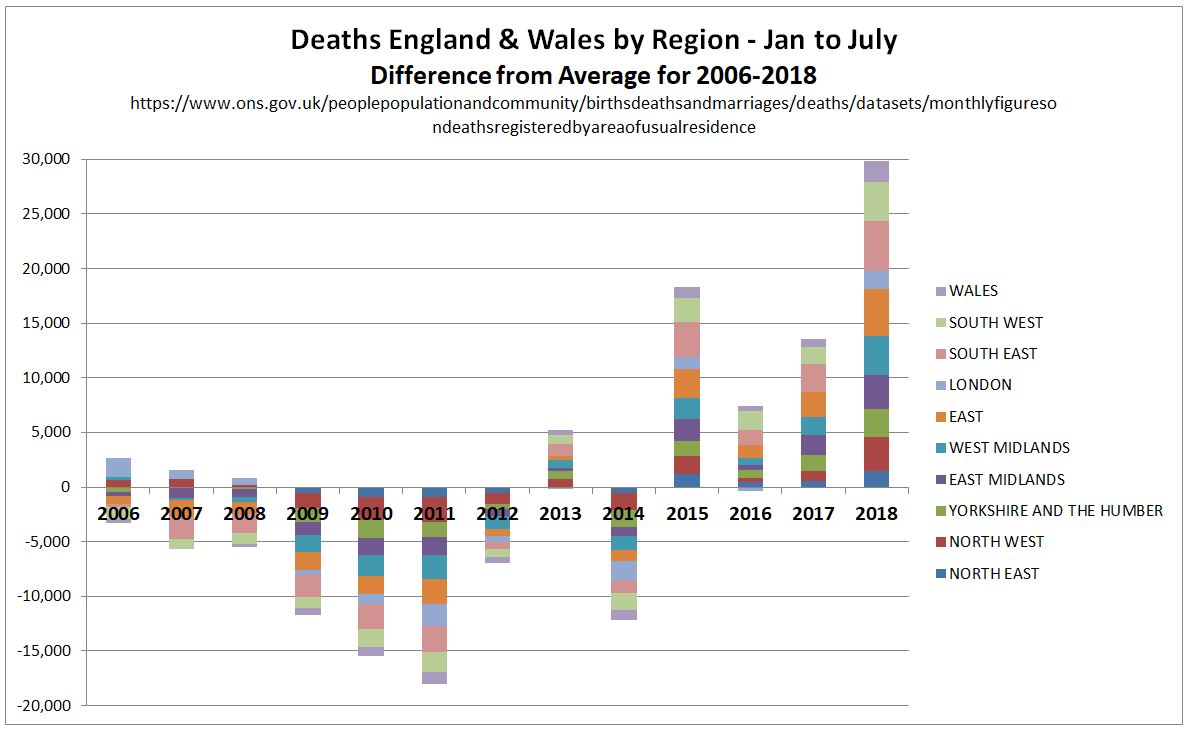
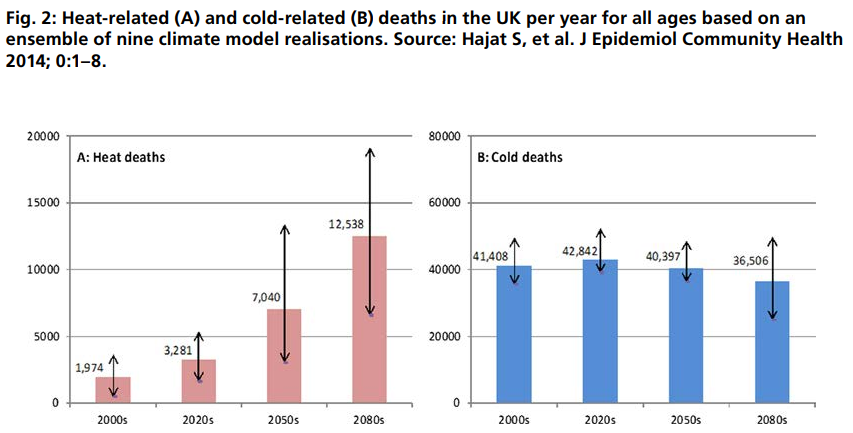
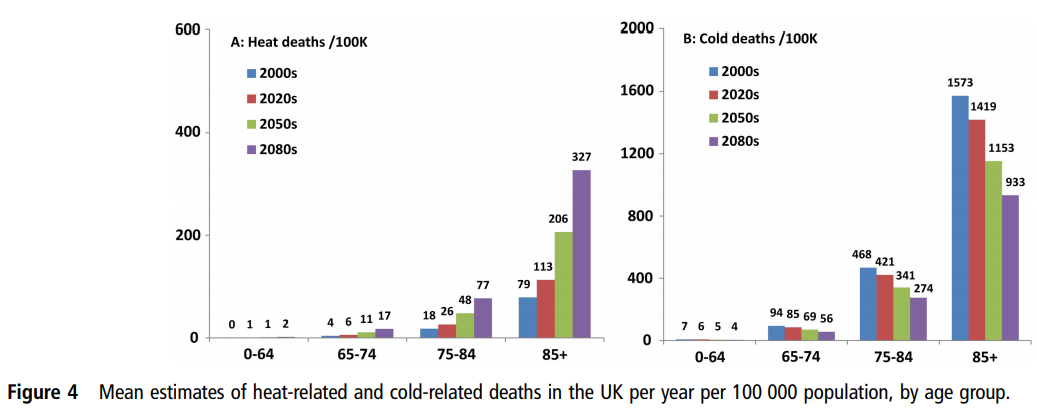
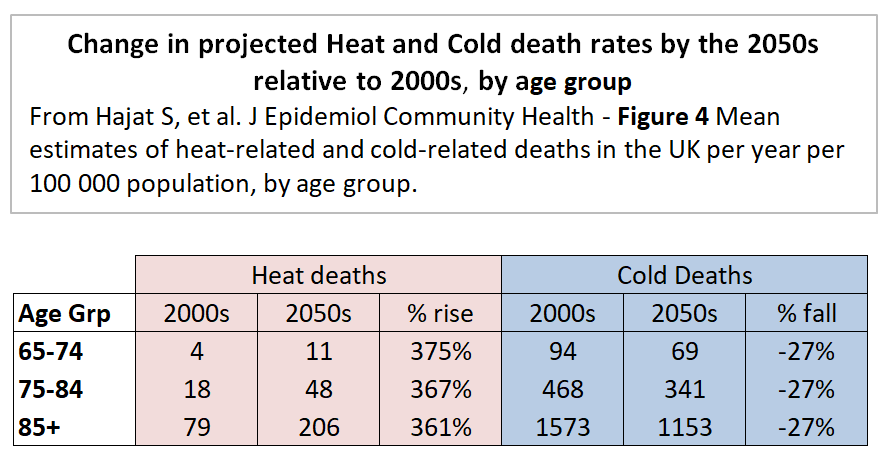
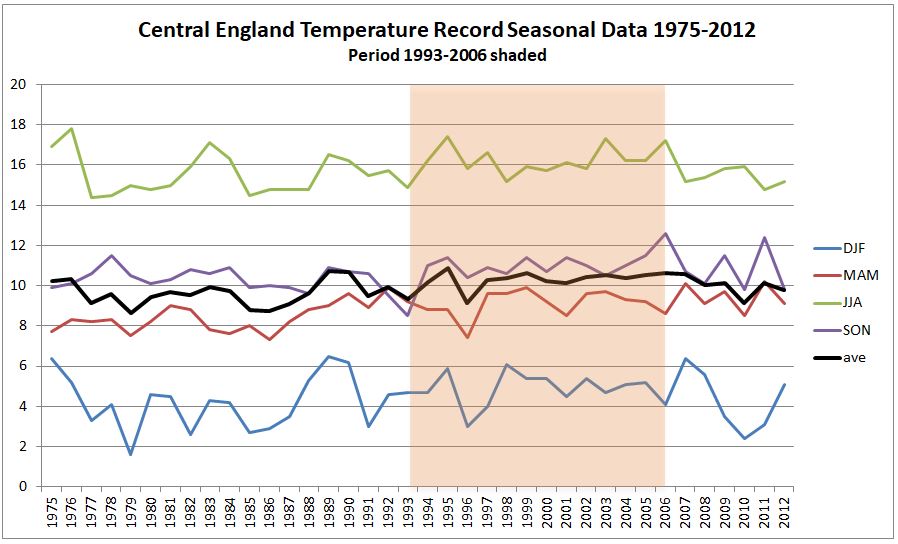
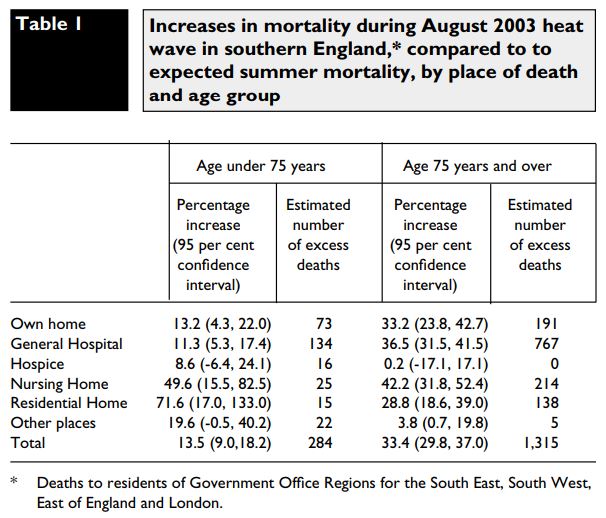
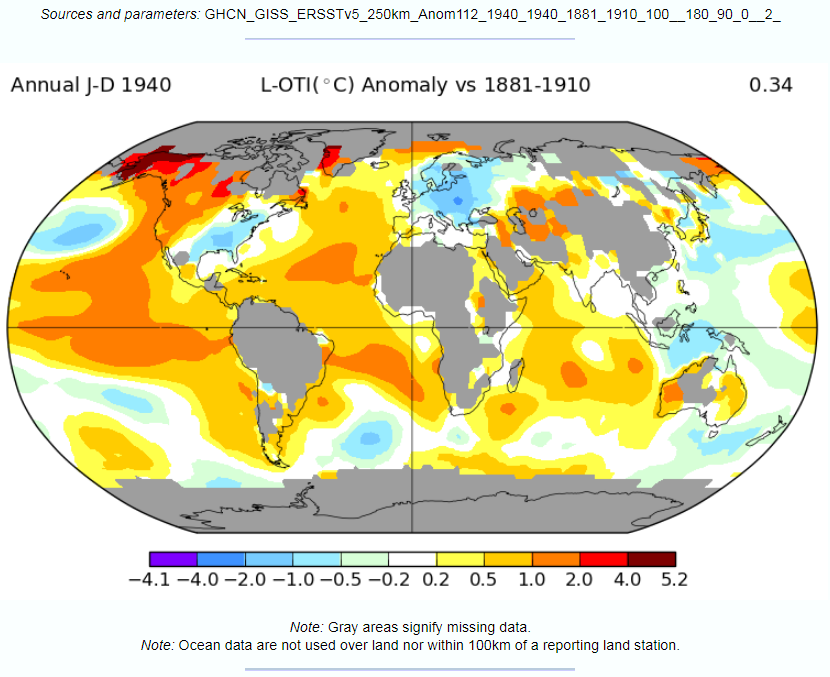
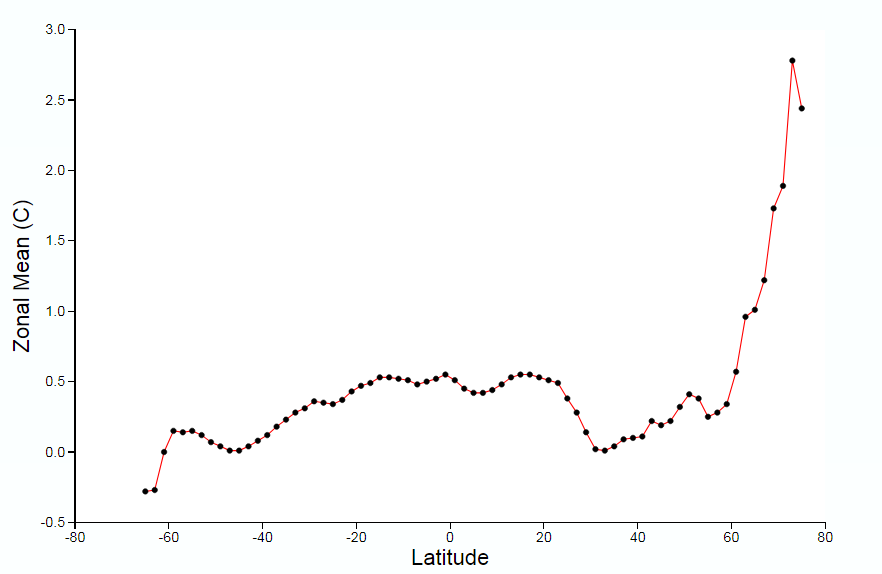
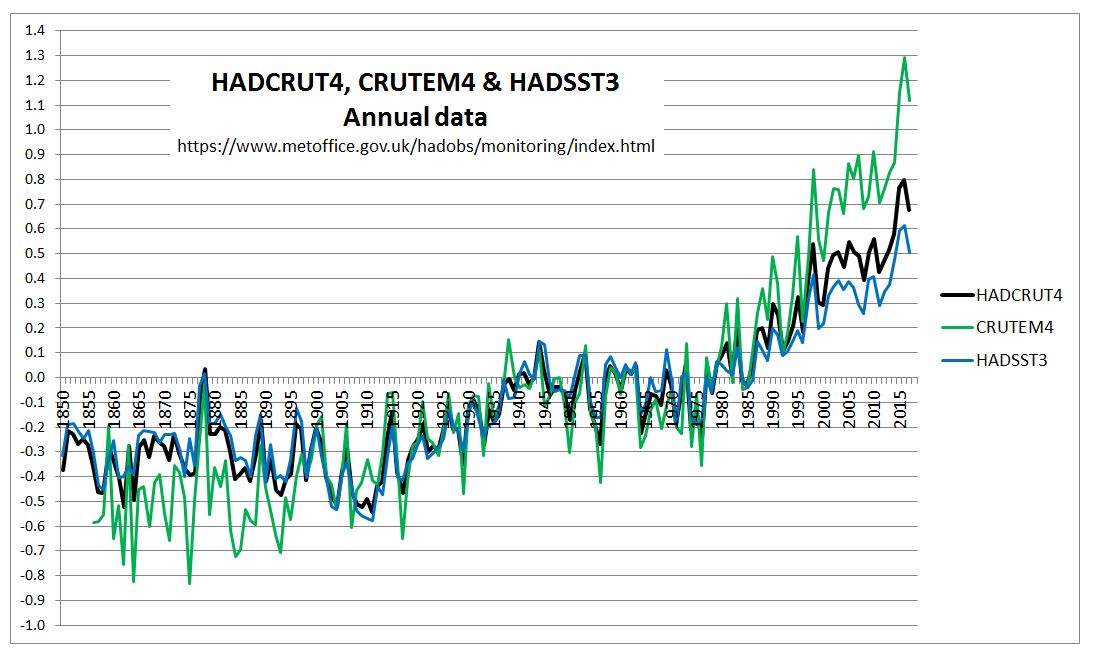
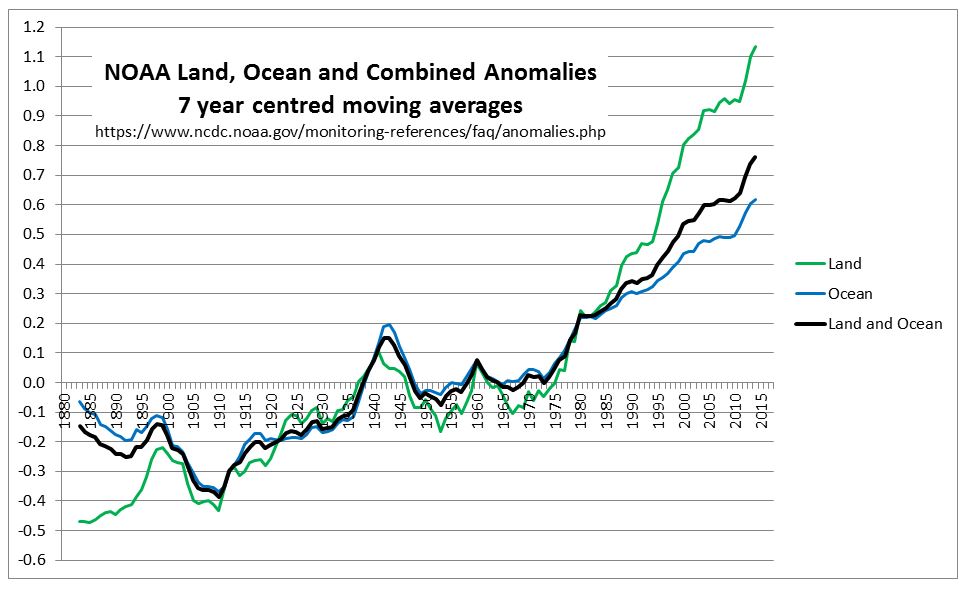
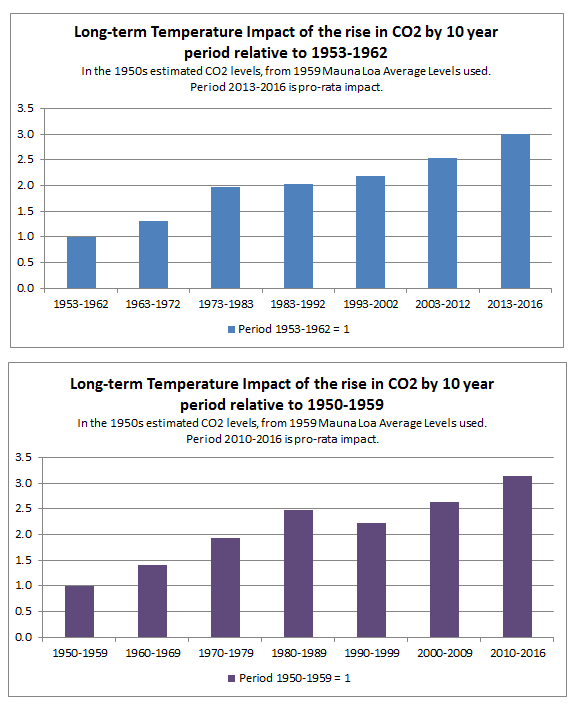
In the previous post I looked at whether the claimed increase in coral bleaching in the Great Barrier Reef was down to global average temperature rise. I concluded that this was not the case as the GBR has not warmed, or at least not warmed as much as the global temperatures. Here I look further at the data.
The first thing to state is that I recognize that heat stress can occur in corals. Blogger Geoff Price (in post at his own blog on April 2nd 2018, reposted at ATTP eleven months later) stated
(B)leaching via thermal stress is lab reproducible and uncontroversial. If you’re curious, see Jones et al 1998, “Temperature-induced bleaching of corals begins with impairment of the CO2 fixation mechanism in zooxanthellae”.
I am curious. The abstract of Jones et al 1998 states
The early effects of heat stress on the photosynthesis of symbiotic dinoflagellates (zooxanthellae) within the tissues of a reef‐building coral were examined using pulse‐amplitude‐modulated (PAM) chlorophyll fluorescence and photorespirometry. Exposure of Stylophora pistillata to 33 and 34 °C for 4 h resulted in ……….Quantum yield decreased to a greater extent on the illuminated surfaces of coral branches than on lower (shaded) surfaces, and also when high irradiance intensities were combined with elevated temperature (33 °C as opposed to 28 °C). …..
If I am reading this right. the coral was exposed to a temperature increase of 5-6 °C for a period of 4 hours. I can appreciate that the coral would suffer from this sudden change in temperature. Most waterborne creatures would be become distressed if the water temperature was increased rapidly. How much before it would seriously stress them might vary, but it is not a serious of tests I would like to carry out. But is there evidence of increasing heat stress causing increasing coral bleaching in the real world? That is, has there been both a rise in coral bleaching and a rise in these heat stress conditions? Clearly there will be seasonal changes in water temperature, even though in the tropics it might not be as large as, say, around the coast of the UK. Also, many over the corals migrate up and down the reef, so they could be tolerant of a range of temperatures. Whether worsening climate conditions have exacerbated heat stress conditions to such an extent that increased coral bleaching has occurred will only be confirmed by confronting the conjectures with the empirical data.
Rise in instances of coral bleaching
I went looking for long-term data that coral bleaching is on the increase and came across and early example.
P. W. Glynn: Coral reef bleaching: Ecological perspectives. Coral Reefs 12, 1–17 (1993). doi:10.1007/BF00303779
From the introduction
Mass coral mortalities in contemporary coral reef ecosystems have been reported in all major reef provinces since the 1870s (Stoddart 1969; Johannes 1975; Endean 1976; Pearson 1981; Brown 1987; Coffroth et al. 1990). Why, then, should the coral reef bleaching and mortality events of the 1980s command great concern? Probably, in large part, because the frequency and scale of bleaching disturbances are unprecedented in the scientific literature.
One such example of observed bleaching is graphed in Glynn’s paper as Figure 1 c
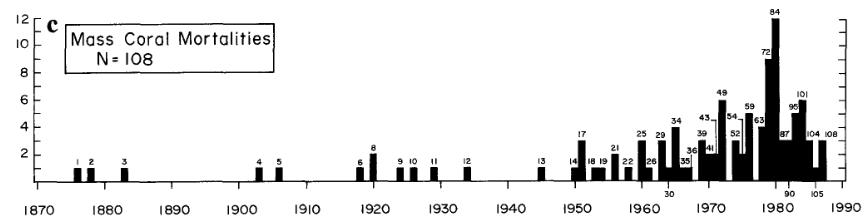
But have coral bleaching events actually risen, or have the observations risen? That is in the past were there less observed bleaching events due to much less bleaching events or much less observations? Since the 1990s have observations of bleaching events increased further due to far more researchers leaving their families the safe climates of temperate countries to endure the perils of diving in waters warmer than a swimming pool? It is only by accurately estimating the observational impact that it is possible to estimate the real impact.
This reminds me of the recent IPPR report, widely discussed including by me, at cliscep and at notalotofpeopleknowthat (e.g. here and here). Extreme claims were lifted a report by billionaire investor Jeremy Grantham, which stated
Since 1950, the number of floods across the world has increased by 15 times, extreme temperature events by 20 times, and wildfires sevenfold
The primary reason was the increase in the number of observations. Grantham mistook increasing recorded observations in a database with real world increases, than embellished the increase in the data to make that appear much more significant. The IPPR then lifted the false perception and the BBC’s Roger Harrabin copied the sentence into his report. The reality is that many extreme weather events occurred prior to the conscientious worldwide cataloguing of them from the 1980s. Just because disasters were not observed and reported to a centralized body did not mean they did not exist.
With respect to catastrophic events in the underlying EM-DAT database it is possible to have some perspective on whether the frequency of reports of disasters are related to increase in actual disasters by looking at the number of deaths. Despite the number of reports going up, the total deaths have gone down. Compared to 1900-1949 in the current decade to mid-2018 “Climate” disaster deaths are down 84%, but reported “Climate” disasters are 65 times more frequent.
I am curious to know how it is one might estimate the real quantity of reported instances of coral bleaching from this data. It would certainly be a lot less than the graph above shows.
Have temperatures increased?
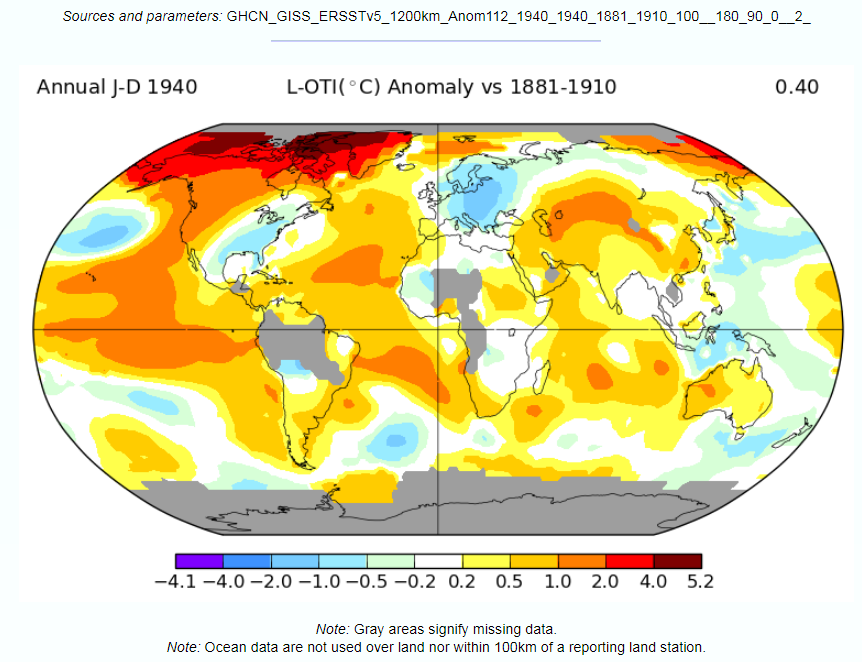
In the previous post I looked at temperature trends in the Great Barrier Reef. There are two main sources that suggest that, contrary to the world as a whole, GBR average temperatures have not increased, or increased much less than the global average. This was shown on the NASA Giss map comparing Jan-2019 with the 1951-1980 average and for two HADSST3 ocean data 5ox5o gridcells. For the latter I only charted the temperature anomaly for two gridcells which are at the North and middle of the GBR. I have updated this chart to include the gridcell 150-155oE / 20-25oS at the southern end of the GBR.
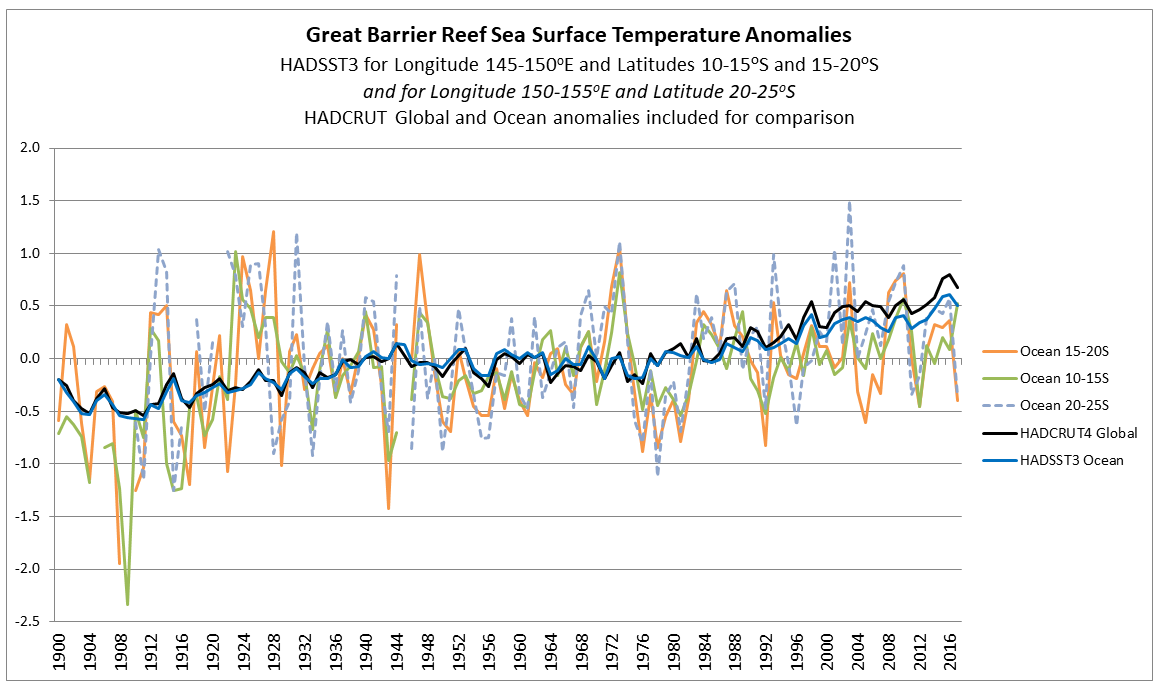
There is an increase in warming trend post 2000, influenced particularly by 2001 and 2003. This is not replicated further north. This is in agreement with the Gistemp map of temperature trends in the previous post, where the Southern end of the GBR showed moderate warming.
Has climate change still impacted on global warming?
However, there is still an issue. If any real, but unknown, increase in coral bleaching has occurred it could still be due to sudden increases in surface sea temperatures, something more in accordance with the test in the lab.
Blogger ATTP (aka Professor Ken Rice) called attention to a recent paper in a comment at cliscep

The link is to a pre-publication copy, without the graphics or supplementary data, to
Global warming and recurrent mass bleaching of corals – Hughes et al Nature 2017
The abstract states
The distinctive geographic footprints of recurrent bleaching on the Great Barrier Reef in 1998, 2002 and 2016 were determined by the spatial pattern of sea temperatures in each year.
So in 2002 the GBR had a localized mass bleaching episode, but did not share in the 2010 pan-tropical events of Rice’s quote. The spatial patterns, and the criteria used are explained.
Explaining spatial patterns
The severity and distinctive geographic footprints of bleaching in each of the three years can be explained by differences in the magnitude and spatial distribution of sea-surface temperature anomalies (Fig. 1a, b and Extended Data Table 1). In each year, 61-63% of reefs experienced four or more Degree Heating Weeks (DHW, oC-weeks). In 1998, heat stress was relatively constrained, ranging from 1-8 DHWs (Fig. 1c). In 2002, the distribution of DHW was broader, and 14% of reefs encountered 8-10 DHWs. In 2016, the spectrum of DHWs expanded further still, with 31% of reefs experiencing 8-16 DHWs (Fig. 1c). The largest heat stress occurred in the northern 1000 km-long section of the Great Barrier Reef. Consequently, the geographic pattern of severe bleaching in 2016 matched the strong north-south gradient in heat stress. In contrast, in 1998 and 2002, heat stress extremes and severe bleaching were both prominent further south (Fig. 1a, b).
For clarification:-
Degree Heating Week (DHW) The NOAA satellite-derived Degree Heating Week (DHW) is an experimental product designed to indicate the accumulated thermal stress that coral reefs experience. A DHW is equivalent to one week of sea surface temperature 1 deg C above the expected summertime maximum.
That is, rather than the long-term temperature rise in global temperatures causing the alleged increase in coral bleaching, it is the human-caused global warming changing the climate by a more indirect means of making extreme heat events more frequent. This seems a bit of a tall stretch. However, the “Degree Heating Week” can be corroborated by the gridcell monthly HADSST3 ocean temperature data for the summer months if both the measures are data are accurate estimates of the underlying data. A paper published last December in Nature Climate Change (also with lead author Prof Terry Hughes) highlighted 1998, 2002, 2016 & 2017 as being major years of coral bleaching. Eco Watch has a short video of maps from the paper showing the locations of bleaching event locations, showing much more observed events in 2016 and 2017 than in 1998 and 2002.
From the 2017 paper any extreme temperature anomalies should be most marked in 2016 across all areas of the GBR. 2002 should be less significant and predominantly in the south. 1998 should be a weaker version of 2002.
Further, if summer extreme temperatures are the cause of heat stress in corals, then 1998, 2002, 2016 & 2017 should have warm summer months.
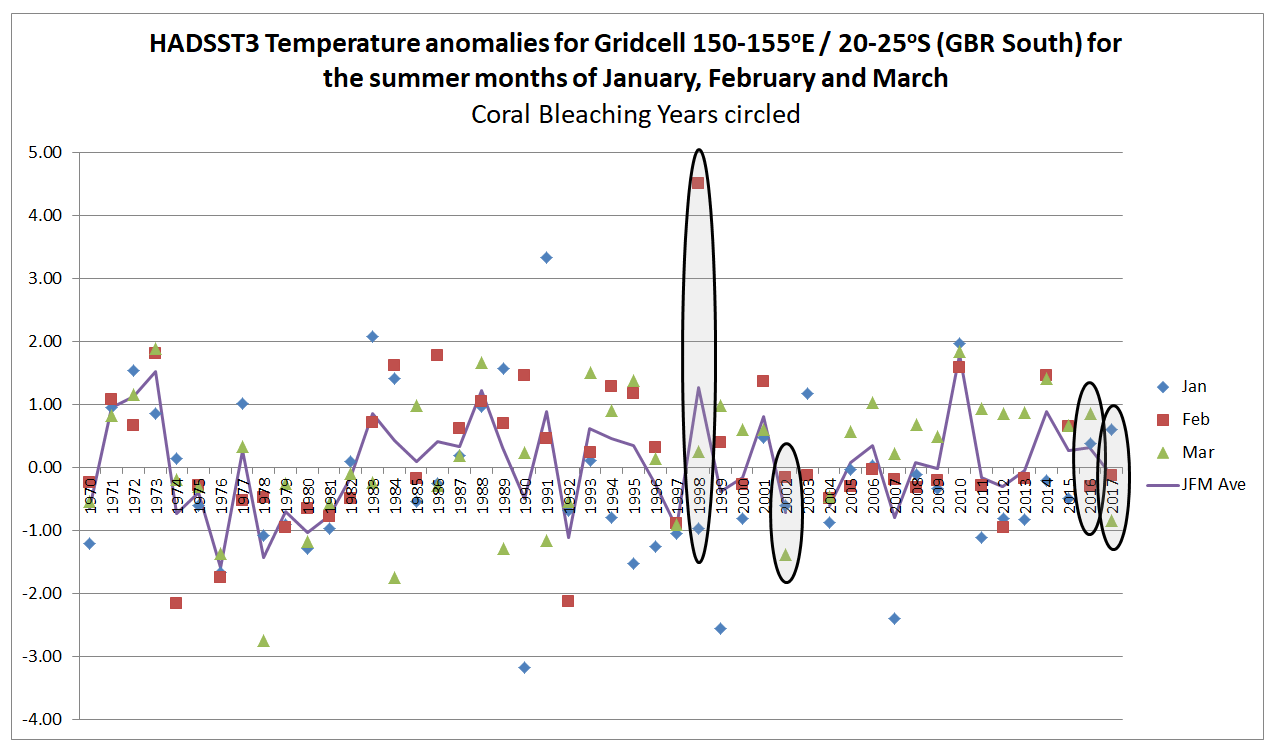
For gridcells 145-150oE / 10-15oS and 150-155oE / 20-25oS respectively representing the northerly and summer extents of the Great Barrier Reef, I have extracted the January February and March anomalies since 1970, then circled the years 1998, 2002, 2016 and 2017. Shown the average of the three summer months.
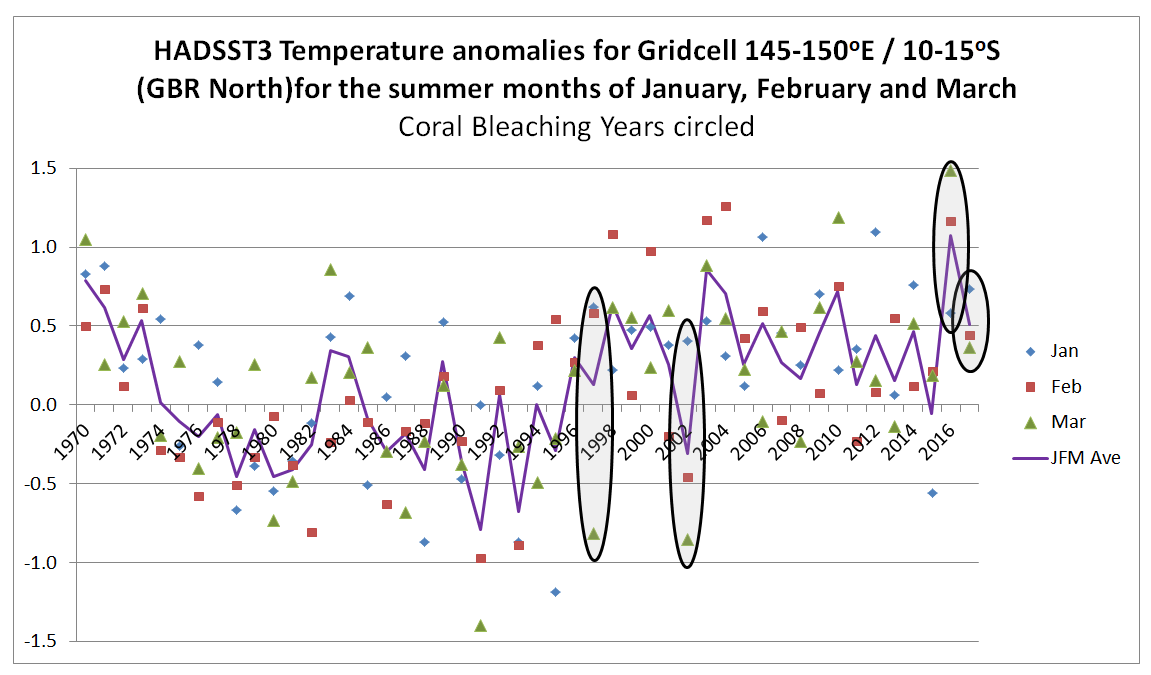
In the North of the GBR, 2016 and 2017 were unusually warm, whilst 2002 was a cool summer and 1998 was not unusual. This is consistent with the papers findings. But 2004 and 2010 were warm years without bleaching.
In the South of the GBR 1998 was exceptionally warm in February. This might suggest an anomalous reading. 2002 was cooler than average and 2016 and 2017 about average.
Also note, that in the North of the GBR summer temperatures appear to be a few tenths of a degree higher from the late 1990s than in the 1980s and early 1990s. In the South there appears to be no such increase. This is the reverse of what was found for the annual average temperatures and the reverse of where the most serious coral bleaching has occurred.
On this basis the monthly summer temperature anomalies do not seem to correspond to the levels of coral bleaching. A further check is to look at the change in the anomaly from the previous month. If sea surface temperatures increase rapidly in summer, this may be the cause of heat stress as much as absolute magnitude above the long-term average.
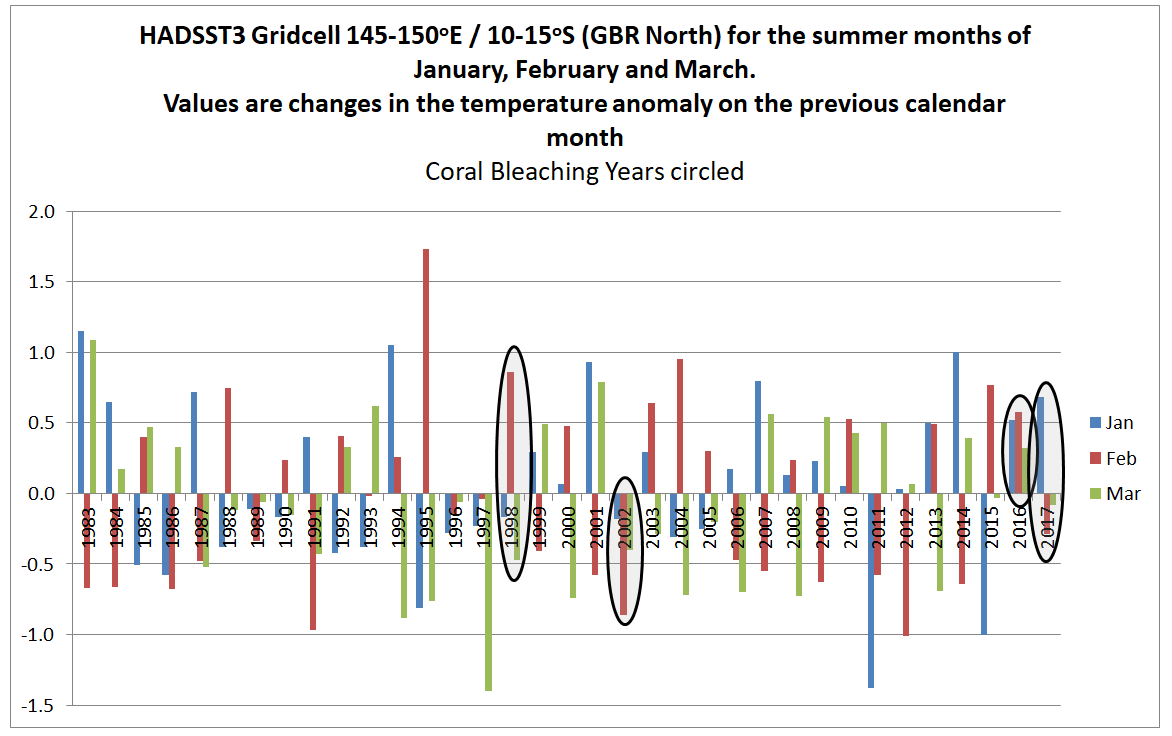
In the North of the GBR the February 1998 anomaly was almost a degree higher than the January anomaly. This is nothing exceptional in the record. 2002, 2016 & 2017 do not stand out at all.
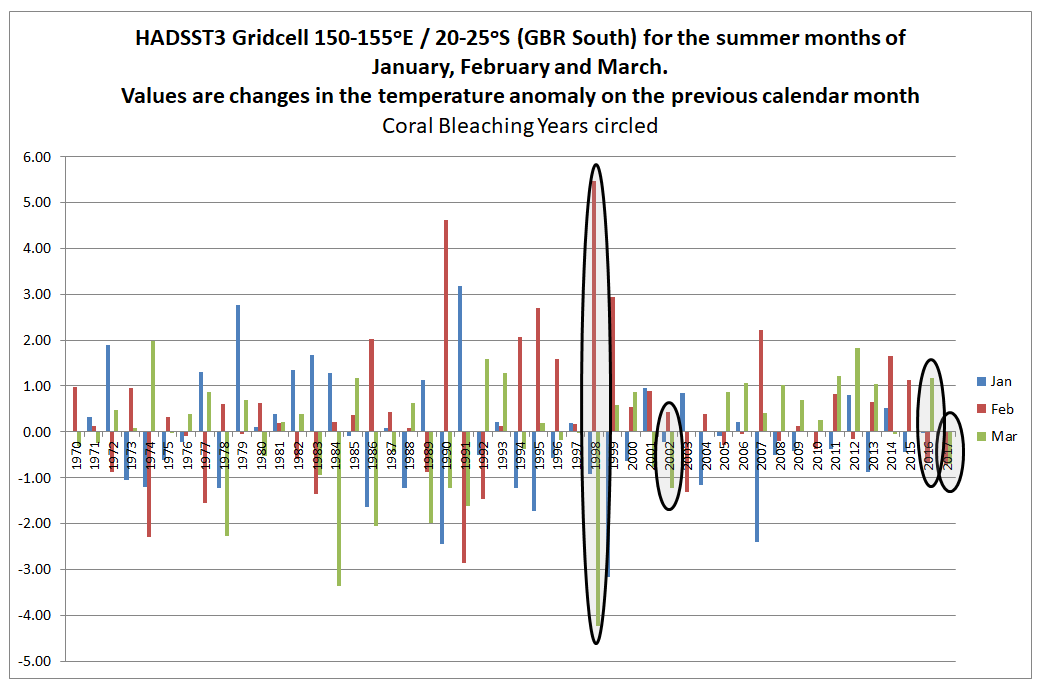
In the South of the GBR, the changes in anomaly from one month to the next are much greater than in the North of the GBR. February 1998 stands out. It could be due to problems in the data. 2002, 2016 and 2017 are unexceptional years. There also appears to be less volatility post 2000 contradicting any belief in climate getting more extreme. I believe it could be an indication that data quality has improved.
Conclusions
Overall, the conjecture that global warming is resulting in increased coral bleaching in the Great Barrier Reeg directly through rising average temperatures, or indirectly through greater volatility in temperature data, is not supported by the HADSST3 surface temperature data from either the North or South of the reef. This does not necessarily mean that there is not a growing problem of heat stress, or though this seems the most likely conclusion. Alternative explanations could be that the sea surface temperature anomaly is inadequate or that other gridcells show something different.
Which brings us back to the problem identified above. How much of the observed increase in coral bleaching is down to real increases in coral bleaching and how much is down to increased observations? In all areas of climate, there is a crucial difference between our perceptions based on limited data and the underlying reality.