Summary
The temperature homogenizations for the Paraguay data within both the BEST and UHCN/Gistemp surface temperature data sets points to a potential flaw within the temperature homogenization process. It removes real, but localized, temperature variations, creating incorrect temperature trends. In the case of Paraguay from 1955 to 1980, a cooling trend is turned into a warming trend. Whether this biases the overall temperature anomalies, or our understanding of climate variation, remains to be explored.
A small place in Mid-Paraguay, on the Brazil/Paraguay border has become the centre of focus of the argument on temperature homogenizations.
For instance here is Dr Kevin Cowtan, of the Department of Chemistry at the University of York, explaining the BEST adjustments at Puerto Casado.
Cowtan explains at 6.40
In a previous video we looked at a station in Paraguay, Puerto Casado. Here is the Berkeley Earth data for that station. Again the difference between the station record and the regional average shows very clear jumps. In this case there are documented station moves corresponding to the two jumps. There may be another small change here that wasn’t picked up. The picture for this station is actually fairly clear.
The first of these “jumps” was a fall in the late 1960s of about 1oC. Figure 1 expands the section of the Berkeley Earth graph from the video, to emphasise this change.
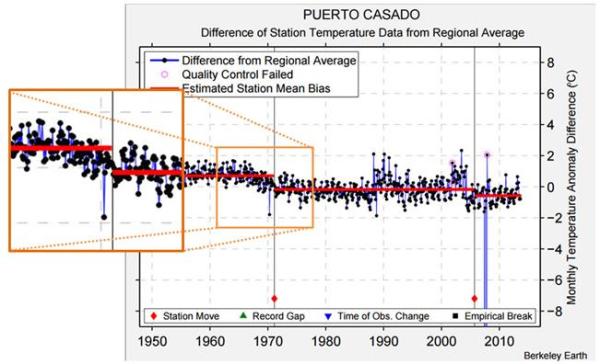
Figure 1 – Berkeley Earth Temperature Anomaly graph for Puerto Casado, with expanded section showing the fall in temperature and against the estimated mean station bias.
The station move is after the fall in temperature.
Shub Niggareth looked at the metadata on the actual station move concluding
IT MOVED BECAUSE THERE IS CHANGE AND THERE IS A CHANGE BECAUSE IT MOVED
That is the evidence of the station move was vague. The major evidence was the fall in temperatures. Alternative evidence is that there were a number of other stations in the area exhibiting similar patterns.
But maybe there was some, unknown, measurement bias (to use Steven Mosher’s term) that would make this data stand out from the rest? I have previously looked eight temperature stations in Paraguay with respect to the NASA Gistemp and UHCN adjustments. The BEST adjustments for the stations, along another in Paul Homewood’s original post, are summarized in Figure 2 for the late 1960s and early 1970s. All eight have similar downward adjustment that I estimate as being between 0.8 to 1.2oC. The first six have a single adjustment. Asuncion Airport and San Juan Bautista have multiple adjustments in the period. Pedro Juan CA was of very poor data quality due to many gaps (see GHCNv2 graph of the raw data) hence the reason for exclusion.
|
GHCN Name |
GHCN Location |
BEST Ref |
Break Type |
Break Year |
|
|
Concepcion |
23.4 S,57.3 W |
Empirical |
1969 |
||
|
Encarcion |
27.3 S,55.8 W |
Empirical |
1968 |
||
|
Mariscal |
22.0 S,60.6 W |
Empirical |
1970 |
||
|
Pilar |
26.9 S,58.3 W |
Empirical |
1967 |
||
|
Puerto Casado |
22.3 S,57.9 W |
Station Move |
1971 |
||
|
San Juan Baut |
26.7 S,57.1 W |
Empirical |
1970 |
||
|
Asuncion Aero |
25.3 S,57.6 W |
Empirical |
1969 |
||
|
|
|
|
Station Move |
1972 |
|
|
|
|
|
Station Move |
1973 |
|
|
San Juan Bautista |
25.8 S,56.3 W |
Empirical |
1965 |
||
|
|
|
|
Empirical |
1967 |
|
|
|
|
|
Station Move |
1971 |
|
|
Pedro Juan CA |
22.6 S,55.6 W |
Empirical |
1968 |
||
|
|
|
|
Empirical |
3 in 1970s |
|
|
Figure 2 – Temperature stations used in previous post on Paraguayan Temperature Homogenisations |
|||||
Why would both BEST and UHCN remove a consistent pattern covering and area of around 200,000 km2? The first reason, as Roger Andrews has found, the temperature fall was confined to Paraguay. The second reason is suggested by the UHCNv2 raw data1 shown in figure 3.
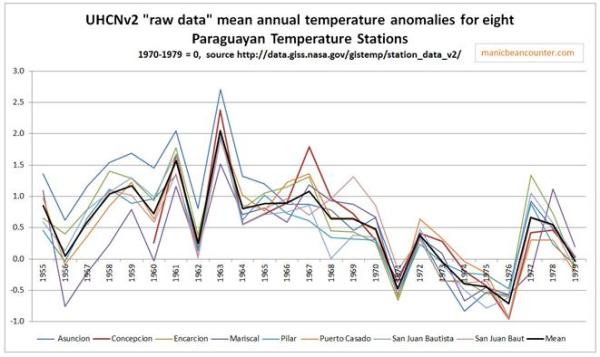
Figure 3 – UHCNv2 “raw data” mean annual temperature anomalies for eight Paraguayan temperature stations, with mean of 1970-1979=0.
There was an average temperature fall across these eight temperature stations of about half a degree from 1967 to 1970, and over one degree by the mid-1970s. But it was not at the same time. The consistency is only show by the periods before and after as the data sets do not diverge. Any homogenisation program would see that for each year or month for every data set, the readings were out of line with all the other data sets. Now maybe it was simply data noise, or maybe there is some unknown change, but it is clearly present in the data. But temperature homogenisation should just smooth this out. Instead it cools the past. Figure 4 shows the impact average change resulting from the UHCN and NASA GISS homogenisations.
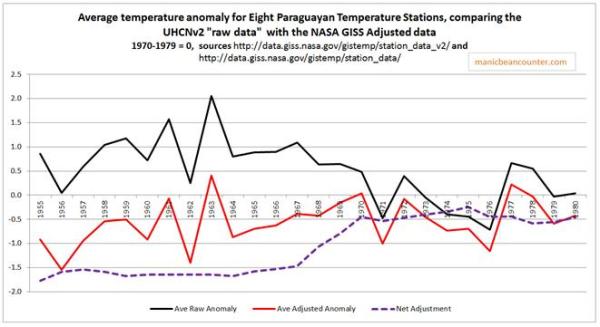
Figure 4 – UHCNv2 “raw data” and NASA GISS Homogenized average temperature anomalies, with the net adjustment.
A cooling trend for the period 1955-1980 has been turned into a warming trend due to the flaw in homogenization procedures.
The Paraguayan data on its own does not impact on the global land surface temperature as it is a tiny area. Further it might be an isolated incident or offset by incidences of understating the warming trend. But what if there are smaller micro climates that are only picked up by one or two temperature stations? Consider figure 5 which looks at the BEST adjustments for Encarnacion, one of the eight Paraguayan stations.
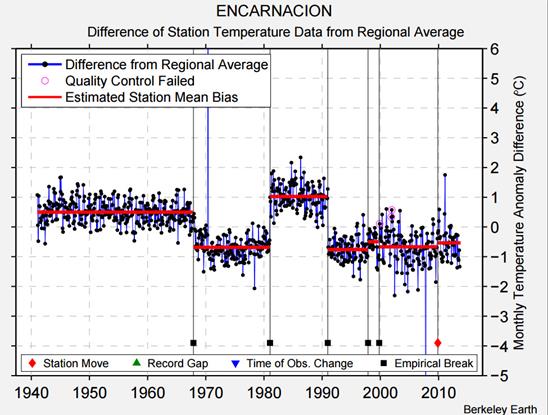
Figure 5 – BEST adjustment for Encarnacion.
There is the empirical break in 1968 from the table above, but also empirical breaks in the 1981 and 1991 that look to be exactly opposite. What Berkeley earth call the “estimated station mean bias” is as a result of actual deviations in the real data. Homogenisation eliminates much of the richness and diversity in the real world data. The question is whether this happens consistently. First we need to understand the term “temperature homogenization“.
Kevin Marshall
Notes
- The UHCNv2 “raw” data is more accurately pre-homogenized data. That is the raw data with some adjustments.

...and Then There's Physics
/ 04/05/2015If you want to understand this, you should really read Nick Stoke’s blog.
Two other things to consider.
Remember that the goal is to extract a climatic signal from the temperature data. In a sense, this is trying to determine what you would get if you were measuring temperature at a fixed, unchanging location, with a perfect sensor that doesn’t change. What you’re calling “richness” is essentially what needs be removed because such changes are almost certainly non-climatic. How can changes to our overall climate produce such changes?
Homogenization refers to the term homogeneous, as opposed to heterogeneous. You want to convert the data into a form that is varies little from site to site. For example, if you simply left it as temperature, and then averaged that, it would be strongly influenced by, for example, how many sensors you had warm locations versus cold; how long each time series was, etc. By converting to anomalies (i.e., temperatures relative to some long-term average
for each site) it makes the data more homogeneous and more suitable for averaging.
There’s more to it than that, but if you want to understand it better, you’d be better of perusing Nick Stoke’s site and asking him some questions, than asking me.
manicbeancounter
/ 04/05/2015Thank you for the comment. You have recognized, as I have said in a number of comments, that homogenization is to make data “homogenous”. If people had understood the implications of this, much of the current kerfuffle over temperature adjustments would not have happened. The biggest issue, in my view, is allowing for the contours in temperature change, whilst recognizing that temperature stations are spatially unevenly dispersed. Gistemp, for instance divides the globe into grids, with the homogenization process loading those detected patterns with the grid onto actual temperature stations. This is my view, but there clearly has to be a cut-off point. Where you have temperature changes over a large area that differs from the global average – such as in the Arctic – it is possible to allow for this. But local patterns can only be partly or fully allowed for. For instance, this could be why in Svalbard – with maybe 7 degrees of recent warming – has been homogenized downwards.
I would suggest that this cut-off point is why the fall in Paraguay temperatures has been homogenized out, not due to it being non-climatic. The BEST homogenization system is different, and looks more rigorous, but achieves the same result. It is due to an information deficit. Whether it is possible to estimate the extent of the biases that this creates I do not know, but it is an interesting line of enquiry to pursue.
It is quite separate from instrumentation biases, and I am concerned that BEST mixes the two up, without trying to fully understand the consequences. Ideally it would be preferable to have detailed history of each locality, then try to estimate the measurement biases before homogenization. This is not possible. But with local variation or noise, this may also create data biases.
Nick Stokes gave his own explanation of the Paraguay anomaly
He says
I do not think this is correct. The drop in temperature anomalies across the eight stations were over 3 to 5 years. Just like a change in citing, a change in measurement devices would surely have an immediate impact? If you look at the raw data both before and after this shift Paraguay is also out of kilter with the rest of the region. Since the late 1970s there has been little or no warming. But all around – including two or three temperature stations in Southern Paraguay – there has.
To emphasize, I do not believe the purpose of data homogenization is to extract the climatic signal. It is to extract the global trends, along with the high-level variances. If the homogenization method were to exclude variations that could not be explained – what you call non-climatic – then the data would be biased towards verifying the theory. If that is really the case (which I do not believe) then Christopher Booker and James Delingpole would have a field day.
...and Then There's Physics
/ 05/05/2015I must admit that I’m not really following what you’re getting at. There are – I think – two somewhat different, but related, processes. The data is adjusted so as to remove non-climatic signals and then homogenised so as to make it more suitable for the averaging. Of course, it’s a bit more complicated than that, but I think that’s broadly the case. You seem to be suggesting that some of these sudden shifts could be climatic, and I’d be interested to know how you think that is possible. Our orbit around the Sun changes very slowly. The Sun itself changes slowly. Oceans cycles tends to produce variability (ENSO events) or change quite slowly (PDO/AMO). So, what physical process could produce a sudden shift in the climate at some location on the planet? I can’t think of one, but maybe you can?
manicbeancounter
/ 05/05/2015We have a difference of approach here.

When I write about temperature contours it was having temperature maps in mind. Here are two different interpretations of the same data. It compares the March 2015 temperature anomaly with the 1981-2010 average. The first is from NOAA and the second from GISS Maps. NOAA’s uses GHCNv3.3, GISS uses GHCNv3b. Basically the same data sets, but GISS includes the estimates for the oceans.
What is clear is that there are huge differences across the globe. There are some large land areas of cooling, especially eastern Canada down to Washington. But there are more areas of warming- particularly Northern Scandinavia and the vast area of Siberia – and the warming is more extreme. There are also huge gaps in the data.
When I have compared GHCNv2 “raw data” with GISS, most of the adjustments & homogenizations were made by GHCN and not by GISS. There is a further stage to extend this analysis to obtain the global anomaly. You can compare a GISS 1200km map with the 250km map to see the difference.
I do not know to reconcile this varied picture from homogenized and adjusted data with any theory. I am not a physicist or a climate scientist, just a beancounter and empiricist. How would you account for the adjusted data saying there are such large variations? My post is saying there appears to another level of complexity below these maps that the homogenization process to some extent erases. Erasing the complexity may be necessary to build up a global anomaly. what is more, much of the information deficit I mention is within the filled-in areas, not the grey areas.
...and Then There's Physics
/ 06/05/2015Okay, I’m still not quite getting what your issue is though. The data in the two maps looks pretty much the same, so I don’t know why you think they show two different approaches. The baseline is 1981-2010 which is probably why you see some cooling and some warming. If the baseline was an earlier period, you would probably see less cooling. Some of the cooling areas are related to ocean cycles (see the recent Mann paper that I can’t quite remember that discusses the cool patch on the NE USA – I think). Are you really expecting the globe to warm uniformly?